PCA slope vs regression slope
Published on Sat 16 May 2026
A regression fit can sometimes look surprisingly poor when plotted on top of data, with the two having visually different slopes. The reason is that the line that visually seems to go through the data best is that which minimizes total projection error, while the least squares fit minimizes squared \(y\)-error at each fixed \(x\) (e.g., see this prior Hacker News thread for discussion). Here, we make these points concrete by working out the exact angular difference between the two fits. We find the effect is strongest when the least squares fit has a slope of \(m = 1/\sqrt{3}\), running \(30\) degrees off the x-axis, as in Figure 1 below.
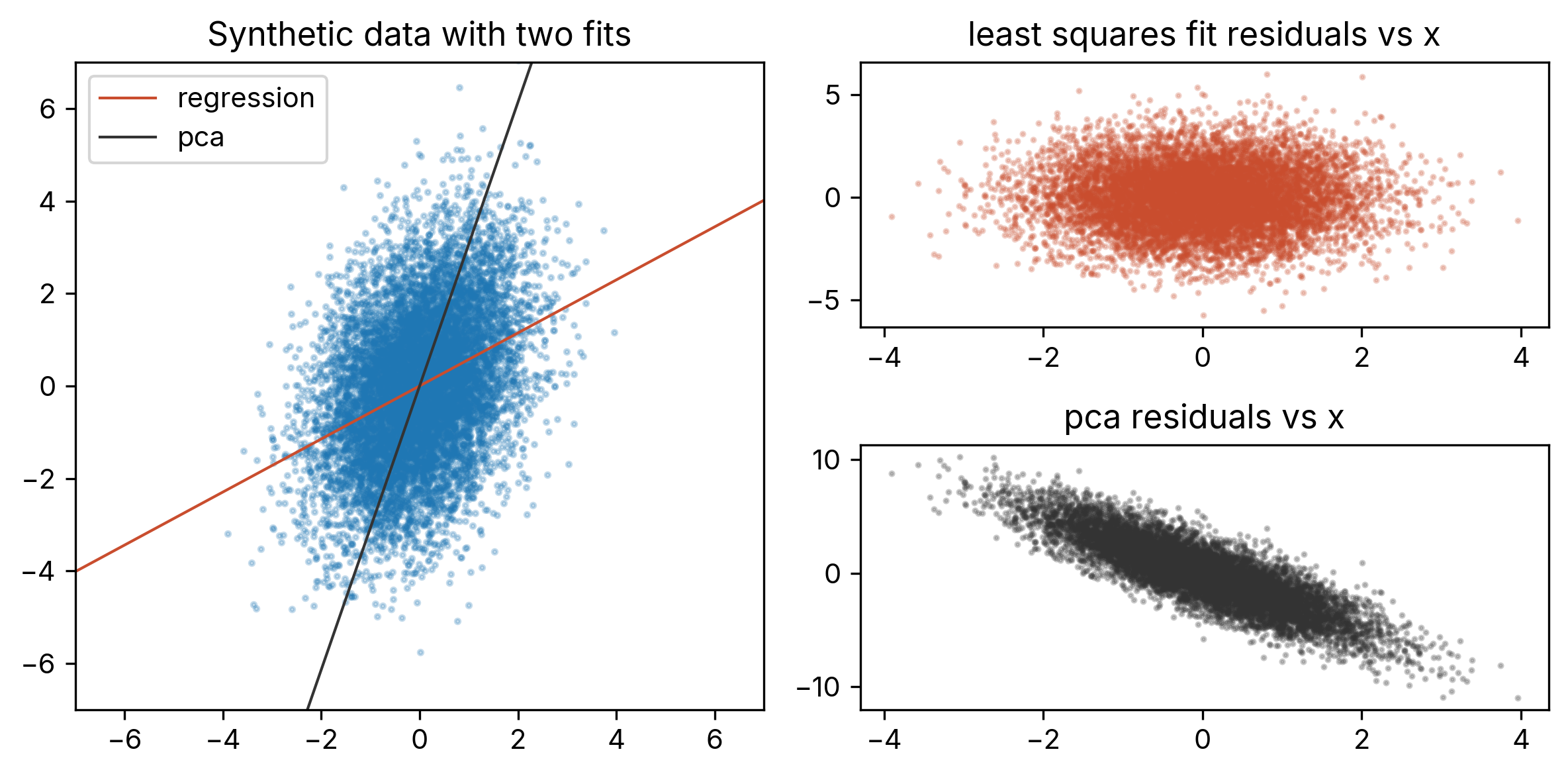
Figure 1: Synthetic data generated from (\ref{1}) with \(m=1/\sqrt{3}\), \(\sigma^2=2.25\). The regression line (red) minimizes squared vertical residuals, while the PCA line (black) minimizes total squared perpendicular distance. Although the PCA line visually seems to fit the data much better, the plots at right show that the least-squares residuals are uncorrelated with \(x\), while PCA residuals show a clear trend.
Evaluating the slope from the two fits
We'll work here with a simple model where \(y\) is related to \(x\) via slope \(m\) and additive noise:
Here, \(\epsilon_i\) has variance \(\sigma^2\). Taking a least-squares fit to plenty of data generated in this way will return a slope of \(m\) and an intercept of \(0\), as expected.
Now, in our prior post on PCA, we reviewed that the PCA direction is the eigenvector corresponding to the largest eigenvalue of the data's covariance matrix. The components of this matrix are as follows: Choosing the scale so that \(E(\delta x^2) = 1\), we have
and
The covariance matrix is then
The eigenvalues of \(C\) are
Again, in PCA we project the data onto the eigenvector corresponding to the larger eigenvalue. This is
where the last line gives the first two terms in the small \(\sigma^2\) limit.
From (\ref{6}), we read out that the PCA slope is given by
Relative to the regression slope \(m\), this is increased by a scale factor of
Maximizing the angular difference
The slope of a line is related to its angle off the \(x\)-axis by
To get the change in angle for our case, we use
Plugging in (\ref{8}), the change in angle is then
The coefficient in front of \(\sigma^2\) is \(\frac{m}{(1+m^2)^2}\), and this is largest at \(m = 1/\sqrt{3}\), where \(\theta = 30\) degrees.